Verkürzte Entwicklungszeiten
Acceleration Stack für Embedded-Vision-Anwendungen
Der Acceleration Stack reVision ermöglicht die Erstellung von softwaredefinierten Lösungen unter Verwendung von Standard-Frameworks und Bibliotheken – mit der Ausrichtung auf Bausteine wie den Zynq-7000 und das Zynq UltraScale+ MPSoC. Damit können Entwickler z.B. Überwachungssysteme erstellen, die den Anschluss mehrerer Bildsensoren erlauben und den Einsatz von eingebetteter Intelligenz und Analytik an der Edge ermöglichen.
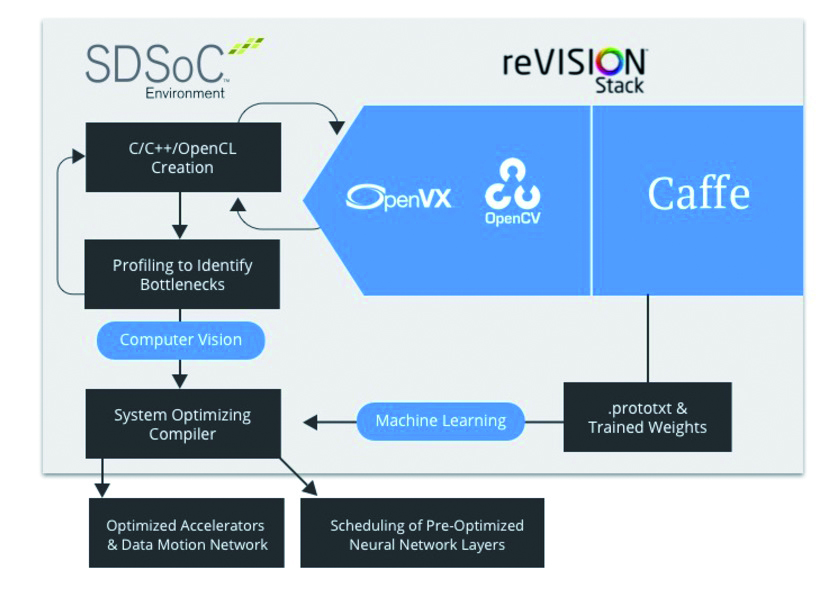
Bild 1 | ReVision Entwicklungsfluss
für Embedded-Vision-und Machine-Learning-Anwendungen. (Bild: Xilinx Inc.)
Moderne Überwachungssysteme basieren weitgehend auf der von Embedded-Vision-Systemen bereitgestellten Funktionalität. Sie werden heute für zahlreiche Applikationen wie Event- und Verkehrs-Monitoring, Safety und Security, bis zu ISR (Intelligence, Surveillance, Reconnaissance) und Business Intelligence eingesetzt. Diese Vielseitigkeit bringt jedoch eine Reihe von Herausforderungen mit sich, die Entwickler bei ihrer jeweiligen Lösung berücksichtigen müssen:
- Unterstützung von Multikamera- und Multisensor-Vision, mit Anschluss homogener oder heterogener Sensortypen.
- Entwicklung mit Standard High-Level Frameworks und Bibliotheken.
- Verarbeitung an der Edge, oft mit eingebettetem Machine Learning, um die gewünschten Fähigkeiten zu realisieren.
- Unterstützung von Echtzeit-Analytik bei höheren Auflösungen und Frameraten.
Je nach vorliegender Applikation implementieren Überwachungssysteme eine Reihe von Algorithmen, vom Optical Flow zur Detektion von Bewegungsabläufen in Bildern, bis zum Machine Learning zur Erfassung und Klassifizierung von Objekten. Heterogene SoC-Bausteine, wie z.B. der All Programmable Zynq-7000 und Zynq UltraScale+ MPSoC, werden zunehmend in der Entwicklung von Überwachungssystemen eingesetzt. Diese Bausteine kombinieren High-Performance ARM-Kerne mit programmierbarer Logik (PL) und schaffen damit leistungsfähige Prozessorsysteme (PS). Die enge Kopplung von PL und PS erlaubt den Aufbau von Systemen, die im Vergleich zu traditionellen Ansätzen deutlich reaktionsschneller und außerdem rekonfigurierbar sind, und eine hohe Leistungseffizienz ermöglichen. Traditionelle CPU-/GPU-basierte Verfahren erfordern den Einsatz von externen Speichern beim Transfer von Bildern von einer Stufe eines Algorithmus zur nächsten. Dies reduziert den Determinismus und erhöht sowohl die Leistungsaufnahme, als auch die Latenz. Heterogene SoCs hingegen ermöglichen die Implementierung der Pipeline zur Bildbearbeitung innerhalb der PL des Bausteins. Damit schaffen sie eine echte Bildbearbeitungs-Pipeline parallel zur PL, wobei der Ausgang einer Stufe den Eingang der nächsten bildet. Dies erlaubt eine deterministische Ansprechzeit mit reduzierter Latenz in einer Leistungs-optimierten Lösung, die zur Unterstützung wachsender Frameraten und Auflösungen geeignet ist. Der Einsatz der programmierbaren Logik (PL) zur Implementierung der Bildbearbeitungs-Pipeline erhöht außerdem die Wahlmöglichkeit beim Interface gegenüber traditionellen Lösungen mit CPU/GPU-SoC, deren Schnittstellen festgelegt sind. Die flexible Natur der I/O-Strukturen in der PL hingegen erlaubt universelle Any-to-Any Konnektivität, ermöglicht also die einfache Implementierung von Schnittstellen im Industrie-Standard, sowie maßgeschneiderte und Legacy Interfaces. Diese Auslegung kann zudem Eingangssignale von mehreren Kameras oder Sensoren verarbeiten. Von entscheidender Bedeutung ist jedoch, dass man die von der Applikation geforderten Algorithmen zügig implementieren kann, ohne das gesamte High-Level Systemmodell in einer Hardwarebeschreibungssprache neu schreiben zu müssen. An diesem Punkt bewährt sich der reVision Stack.
ReVision Stack

Bild 2 | Verkürzte Entwicklungszeiten mit reVision und SDSoC. (Bild: Xilinx Inc.)
ReVision fungiert als Acceleration Stack. Er ermöglicht den direkten Einsatz von OpenCV, OpenVX und Caffe bei der Entwicklung von Embedded-Vision- und Machine-Learning-Applikationen, einschließlich Überwachungssysteme. Für reaktionsschnelle Lösungen kann man mit dem Stack sowohl die OpenCV-Funktionen, als auch Caffe-basierte Inferenzmaschinen für Machine Learning innerhalb der programmierbaren Logik beschleunigen. Natürlich ergibt sich mit der Beschleunigung in der PL ein signifikanter Gewinn an Performance, gleichbedeutend mit höherem Determinismus und geringerer Latenz. Diese Fähigkeit zur Beschleunigung wird vom SDSoC bereitgestellt, das als Compiler zur Systemoptimierung fungiert und die Software-definierte Entwicklung mit dem All Programmable Zynq SoC oder dem Zynq UltraScale+ MPSoC erlaubt. Maßgebend dafür ist die Kombination der Vivado High-Level Synthese (HLS) mit einem Konnektivitäts-Framework, was die nahtlose Verschiebung von Funktionen zwischen dem PS und dem PL ermöglicht. Diese Auslegung erleichtert die Erstellung optimaler Lösungen, mit Funktionen, die entweder im PS oder in der PL residieren können, um die beste Gesamtperformance zu erzielen. Die Identifizierung von Funktionen, die Engpässe für die Performance darstellen können, und deshalb Kandidaten für eine Beschleunigung sind, geschieht mithilfe der eingebauten Pofiling-Fähigkeiten des SDSoC.
42x höhere Werte pro Watt
Benchmark-Tests der Entwicklung mit reVision zeigen einen deutlichen Zuwachs an Performance: einen bis zu 42-fach höheren Wert pro Sekunde pro Watt für die Bildverarbeitung und die sechsfache Zahl von Bildern pro Sekunde pro Watt in Machine Vision Applikationen. Außerdem realisiert der Stack im Vergleich zur traditionellen RTL-basierten Entwicklung eine signifikante Verkürzung der Entwicklungszeit. Der traditionelle Flow hingegen bedingt eine Diskrepanz zwischen den Algorithmen für High-Level Embedded Vision und Machine Learning und dem in der PL implementierten RTL-Design. Das würde bedeuten, dass die High-Level Algorithmen in RTL neu erstellt werden müssten, was den Zeitaufwand und die Kosten der Entwicklung erhöht. Außerdem würde dies zu einer rigiden Systemsegmentierung zwischen dem PS und der PL führen, und damit die Möglichkeit der Verlagerung von Funktionalitäten beseitigen. Der Einsatz von reVision und des SDSoC beseitigt diese Diskrepanz und ermöglicht die volle Konzentration auf für die Wertschöpfung relevanten Aktivitäten. Damit ergibt sich eine kürzere Time-to-Market bei geringeren Entwicklungskosten.










