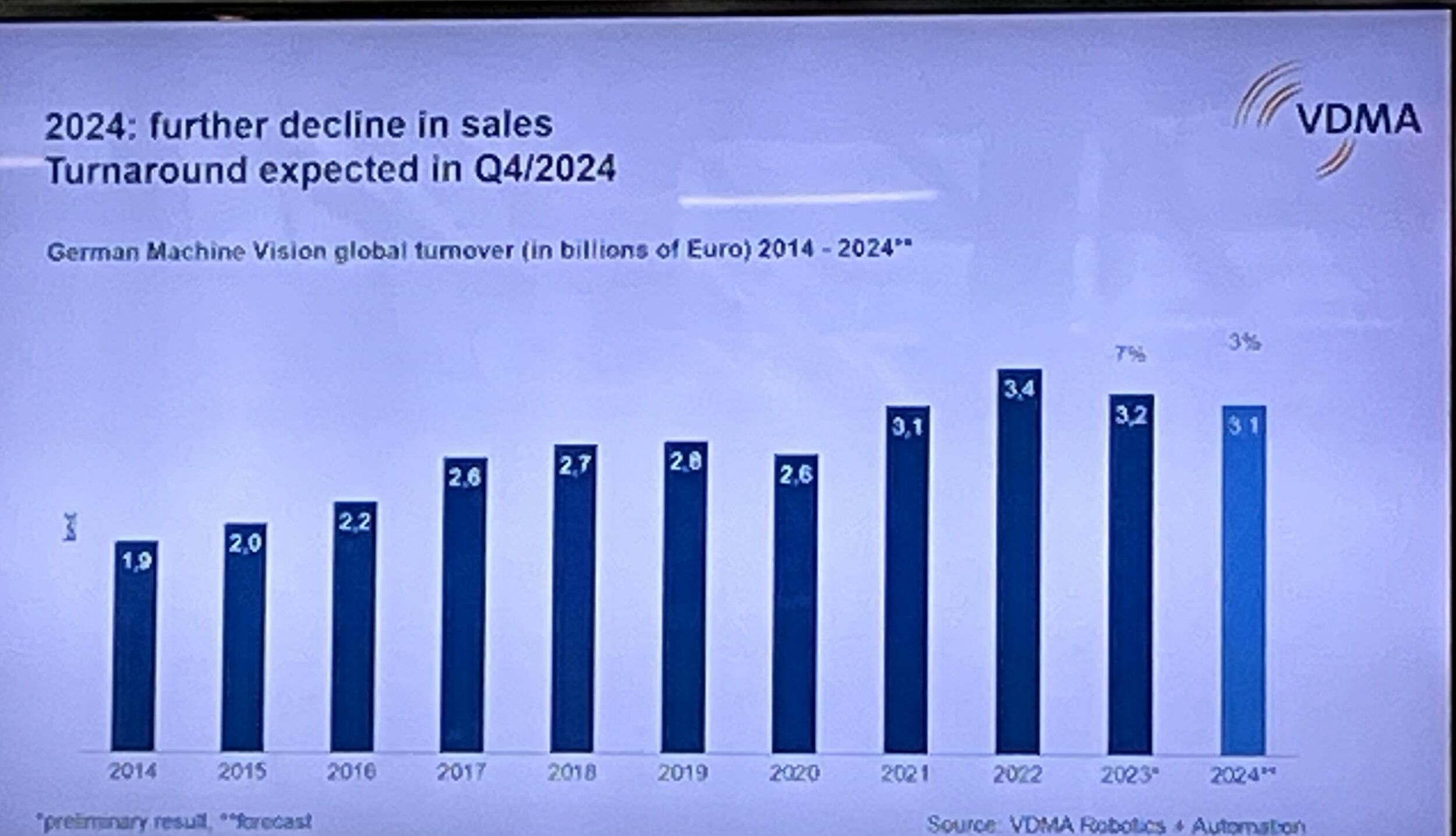
")
Die FPGA-Leistung ist zwar 7,3-mal höher als die einer GPU, der Verlust an der Vorhersagegenauigkeit liegt aber bei 0,3 Prozent, was 30 Prozent mehr inkorrekt klassifizierten ern entspricht. (Bild: Silicon Software GmbH)
Vergleich FPGA vs. GPU
Für hohe Bandbreiten kommen nur FPGAs oder GPUs als Technologie in Betracht. Eine Gegenüberstellung der jeweiligen Schwächen und Stärken zeigt, dass die höhere Rechengenauigkeit von GPUs und damit auch höhere Genauigkeit durch deutlich kürzere Verfügbarkeiten, höhere Leistungsaufnahme aber auch durch eine geringeren Datendurchsatz erkauft wird. Die Leistung der Datenbearbeitung liegt bei den FPGAs um den Faktor 7,3 höher als bei vergleichbaren GPUs. Der Gewinn bei der Genauigkeit liegt bei 0,3 Prozent, bedeutet aber eine 30 Prozent höhere Anzahl falsch klassifizierter Bilder. Im Vergleich der Systemkosten für eine Inferenz wurden Rechensysteme basierend auf einem programmierbaren FPGA-Framegrabber, einer speziellen Branchensoftwarelösung mit zwei GPUs und zwei Standardsystemen mit einer industriellen und kommerziellen GPU herangezogen. Die Kosten wurden über die Komponenten für einen Framegrabber (hier eine industrielle Camera Link Lösung), eine oder mehrere GPUs, einen industriellen Rechner und anfallende Softwarelizenzen ermittelt. Nicht berücksichtigt wurde bei der Gegenüberstellung die Leistungswerte für Datendurchsatz, Bandbreite und Energieeffizienz. Die Kehrseite vermeintlich preisgünstiger Systeme sind eine geringe Lieferbarkeit und schlechtere Performance. Ein Upgrade zu industriellen Produkten (auch GPUs) führt sofort zu höheren Preisen als FPGA-basierte Systeme. Branchenlösungen können dagegen durch unterschiedliche Lizenzmodelle (Jahreslizenz, Arbeitsplatzlizenz oder Koppelung) hohe Kosten erzeugen, welche die Hardwarekosten schnell übersteigen.
Implementierung auf FPGAs
Die Rechenleistung von FPGAs hat sich in einem Maße entwickelt, die das Wachstum von herkömmlichen Prozessoren deutlich überflügelt. Der Produktionsprozess von FPGAs wird aktuell von 16 auf 7nm umgestellt, das heißt eine Vervielfachung der Logikreserven um den Faktor 10. Mit der Umstellung auf 3nm in ca. fünf Jahren wird sogar ein Faktor 100 im Vergleich zu heute erreicht. Dadurch lassen sich komplexe Algorithmen implementieren und Objekte in einem Bild automatisch klassifizieren. Um die bei vielen Deep-Learning-Anwendungen geforderte hohe Rechengeschwindigkeit zusammen mit einer hohen Durchsatzrate und Treffgenauigkeit zu erzielen sowie für die Implementierung großer Netze sind allerdings auch leistungsfähigere FPGAs notwendig. Für die in der Produktion erforderlichen Verarbeitungsgeschwindigkeiten stehen bereits Hochleistungs-Framegrabber und eingebettete Bildverarbeitungsgeräte wie Kameras und Sensoren mit größeren FPGAs zur Verfügung. Mit umfangreicheren FPGA-Ressourcen lassen sich komplexere Architekturen und damit auch Anwendungen verarbeiten. Die höhere Datenbandbreite ermöglicht eine Verarbeitung eines Gesamtbildes oder zusätzliche Bildvor- und -nachverarbeitung auf dem FPGA. Sie ist ausreichend hoch, um z.B. den kompletten Datenausgang einer GigE Vision Kamera mit Deep Learning zu analysieren.
FPGA-Ressourcen optimieren
Die Bearbeitungsmöglichkeiten im FPGA stehen im direkten Zusammenhang mit den verfügbaren Logikressourcen. Diese können für die algorithmische Beschreibung, aber auch für aufwändige Implementierungsmethoden, Rechentiefen oder höhere Bandbreiten über die Vervielfachung des Rechenkerns eingesetzt werden. Für Deep Learning gibt es unterschiedliche Methoden, Ressourcen einzusparen ohne die Qualität der Klassifizierung zu beeinträchtigen. Eine Methode ist die Skalierung der Bilder, die den internen Datendurchfluss reduziert. Erfahrungswerte haben gezeigt, dass die Rechentiefe sich nur marginal auf die spätere Erkennungsgenauigkeit durchschlägt. Die Reduktion von 32Bit auf 8Bit und von Floating Point auf Fixed Point / Integer ermöglicht dem FPGA, seine stark eingesparten Ressourcen in größere Netzarchitekturen zu investieren. Die höhere Rechengenauigkeit einer 32Bit Floating Point GPU ist für die Deep Learning Inference von geringer Bedeutung, erreichen doch 8Bit Fixed Point FPGAs eine ausreichend präzise Erkennungsgenauigkeit für die meisten Deep-Learning-Anwendungen bei zu vernachlässigender Fehlertoleranz. Bei Anforderungen nach besonders präziser Rechengenauigkeit lässt sich auf einem größeren FPGA als Ressourcenkompromiss auch 16Bit Fixed Point implementieren. Typische Aufgabenstellung in der Bildverarbeitung ist die Erkennung von Defekten. Sind die Fehlerklassen bekannt, lassen sie sich anhand von Defektbildern aus der Produktion antrainieren. Hingegen bei unbekannten Bildern und der Anforderung, jede Abweichung zu erkennen, werden die Prüfstücke mit einem Golden Master verglichen. In jedem dieser Fälle sind meist kleine Netze einzusetzen, die Fehlerklassen und deren Varianten detektieren. AlexNet, SqueezeNet oder MobileNet sind typische Vertreter hierfür. Diese sind als Basis für spezifische Anpassungen und Verbesserungen der Netzarchitektur für die individuelle Anwendung einsetzbar. Nach dem Training folgt die FPGA-Implementierung für die Inference, das heißt eine weitere Möglichkeit, Ressourcen zu optimieren und die Klassifizierungsqualität zu erhöhen. Im Verhältnis zwischen Erkennungsgenauigkeit, Implementierungsgröße und Rechengeschwindigkeit bzw. Bandbreite werden bei Machine Vision vorrangig kleine, schnelle Netze eingesetzt.