Dies verändert auch, wo im System Engineering Zeit investiert werden muss, welche Kompetenzen Integratoren brauchen und welche Hersteller tatsächlich die Erfahrung mitbringen, um in diesen Umgebungen zuverlässig zu liefern. Die Bildverarbeitung verschiebt sich zunehmend von CPU-basierten Architekturen hin zu GPU-beschleunigten Pipelines, oft kombiniert mit Edge-Computing direkt am Sensor. In solchen Systemen ist das Aufnehmen des Bildes längst nicht mehr die eigentliche Herausforderung. Entscheidend ist, was danach mit den Daten passiert.
CMOS-Sensoren haben sich in den vergangenen Jahren mit beeindruckender Geschwindigkeit weiterentwickelt. Sony hat dabei mit den Pregius- und Pregius-S-Plattformen maßgeblich die Richtung vorgegeben. Höhere Auflösungen, bessere Empfindlichkeit und stetig steigende Bildraten ermöglichen Anwendungen, die vor wenigen Jahren kaum realisierbar waren. Gleichzeitig hat genau dieser Fortschritt aber auch die Herausforderungen im Visionsystem verschoben. Lange Zeit lag der Engpass entweder im Sensor selbst oder in der Schnittstelle, die die Bilddaten zum Host-System transportiert. Heute ist das oft nicht mehr der Fall. Moderne Sensoren erzeugen enorme Datenmengen, und Schnittstellen wie 100GigE sind in der Lage, die Daten zuverlässig zu übertragen. Die eigentliche Herausforderung beginnt erst, nachdem die Daten die Kamera verlassen haben.

Wenn aus PowerPoint Realität wird
In den vergangenen Monaten haben mehrere Kamerahersteller ihre ersten 100GigE-Kameras auf den Markt gebracht. Viele dieser Plattformen existierten zuvor jahrelang hauptsächlich auf Produktroadmaps und in Präsentationsfolien. Ihre wachsende Verfügbarkeit ist ein wichtiger Schritt für die Branche, denn Highspeed-Ethernet öffnet Anwendungen, die bisher spezialisierte und kostspielige Hardwareschnittstellen erfordert haben, und bringt Visionsysteme näher an moderne Rechenzentrumsarchitekturen heran.
Was aber in der aktuellen Ankündigungswelle leicht untergeht: Hochbandbreitiges Ethernet in der Bildverarbeitung ist nicht neu. Emergent Vision hat vor über zwölf Jahren die ersten 10GigE-Kameras eingeführt, vor mehr als acht Jahren folgten 25GigE-Plattformen, und vor über sechs Jahren kamen die ersten 100GigE-Kameras auf Basis von Gpixel-Sensoren auf den Markt. Diese Systeme wurden von Anfang an für Anwendungen entwickelt, in denen klassische Visionarchitekturen schnell an ihre Grenzen stoßen: großangelegte Multi-Kamera-Inspektionssysteme, volumetrische Capture-Setups, wissenschaftliche Bildgebungsplattformen und Highspeed-Bewegungsanalysen, bei denen die Kameraanzahl nicht in Einzelstücken, sondern in Dutzenden gemessen wird. Mehr als ein Jahrzehnt Arbeit in diesen Umgebungen hat zu einer einfachen Erkenntnis geführt: Die Kamera selbst war selten der Flaschenhals, der entscheidende Faktor war fast immer die Systemarchitektur dahinter.
Sony-Sensoren erweitern 100GigE-Plattform
Bislang basieren alle 100GigE-Flächenscan- und Zeilenkameras von Emergent auf der Sensorfamilie von Gpixel. Der nächste Schritt kommt nun von Sonys neuesten Image Sensoren. Deren aktuelle CMOS-Sensoren auf Basis der vierten Pregius-S-Generation kombinieren hohe Auflösung, hohe Bildraten und verbesserte Empfindlichkeit in einer kompakten Pixelarchitektur. Mit Pixelgrößen von 5,48 bis 2,74µm ermöglichen die Sensoren deutlich höhere Auflösungen, ohne Abstriche bei der Bildqualität und Effizienz. Das Portfolio deckt ein breites Leistungsspektrum ab, von hochdynamischen Sensoren im mittleren Auflösungsbereich bis hin zu Plattformen mit über 100MP. Die ersten Emergent Kamera-Modelle der neuen Generation, darunter die HZ-12000-SB (IMX926), HZ-25000-SB (IMX925) und HZ-100-SB (IMX927), befinden sich bereits in Serienproduktion. Weitere Modelle folgen bis Ende 2026 bzw. Anfang 2027. Sonys Roadmap umfasst auch Varianten der großformatigen Sensoren mit reduzierter Bildrate, etwa die IMX937- und IMX938, die sich an Anwendungen richten, bei denen maximale Auflösung gefragt ist, aber nicht die volle Sensorgeschwindigkeit. Diese Varianten eröffnen zusätzliche Freiheitsgrade im Systemdesign, da sie je nach Anforderung auch mit 10GigE- oder 25GigE-Schnittstellen kombiniert werden können und damit kosteneffizientere Architekturen bei hoher Bildqualität ermöglichen. Zukünftige Kameraplattformen auf Basis dieser Sensoren werden das bestehende 100GigE-Portfolio von Emergent ergänzen sowie die etablierten 10GigE-Eros- und 25GigE-Bolt-Familien erweitern.
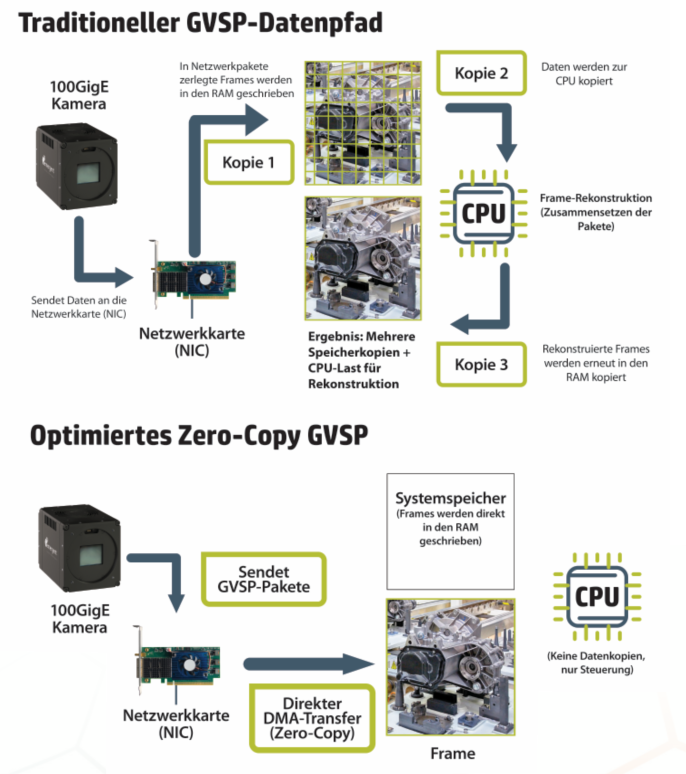
Die GVSP-Herausforderung und wie man sie löst
In der industriellen Bildverarbeitung ist GigE Vision seit Jahren die etablierte Schnittstellenlösung im unteren Bandbreitenbereich, von 1 über 2,5 bis 5GigE. Das GigE Vision Streaming Protocol (GVSP) ist dabei der Teil des Standards, der den eigentlichen Bilddatentransport übernimmt. Seine Stärken sind bekannt: Standard-Netzwerkinfrastruktur, breite Softwarekompatibilität, kein proprietärer Hardware-Lock-in. Emergent hat GigE Vision seit über einem Jahrzehnt konsequent in den Highspeed-Bereich weiterentwickelt, lange bevor der Rest der Branche nachzog. Die Herausforderungen, die mit der Skalierung auf 10, 25 und 100GigE einhergehen, sind daher für das Unternehmen kein Neuland.
Ein aktuelles Kundenprojekt macht dies greifbar. Ein Hersteller in der Lebensmittelverarbeitung benötigte ein KI-basiertes optisches Inspektionssystem mit bis zu 21 gleichzeitig laufenden Kameras. Sämtliche Bilddaten wurden über einen einzigen Netzwerk-Switch an ein Host-System mit drei GPUs geleitet, auf dem der KI-Inferenzcode des Kunden lief und den vollständigen Kamerastream in Echtzeit verarbeitete, ohne Toleranz für Frameverluste oder Verzögerungen. Über zwei Jahre lang hatte der Kunde versucht, diese Architektur zum Laufen zu bringen. Die Hardware war auf dem Papier zwar leistungsfähig, aber in der Praxis war ein stabiler Betrieb bei der geforderten Kameraanzahl nicht möglich. Der CPU-Overhead klassischer GVSP-Implementierungen sättigte den Host, noch bevor die GPU-Pipeline überhaupt zur limitierenden Größe werden konnte. Frames gingen verloren, die Latenz war inkonsistent, die KI-Inferenzergebnisse unzuverlässig. Als Emergent hinzugezogen wurde, lief danach das vollständige 21-Kamera-Setup auf demselben einzelnen Host stabil, mit 10GigE-Kameras, einem optimierten GVSP-Treiberstack und einem schlüsselfertigen Aufbau auf Basis von eCapture Pro, Emergents Echtzeit-Multi-Kamera-Aufnahme- und Verarbeitungssoftware mit grafischer Oberfläche für Systemeinrichtung, Monitoring und Datenhandling. Der KI-Inferenzcode des Kunden wurde als Custom-Plugin in dieses Framework integriert und verarbeitete die eingehenden Bildströme direkt, ohne zusätzlichen Datenhandling-Overhead. Damit entfiel die Notwendigkeit, weite Teile der Aufnahme-, Visualisierungs- und Laufzeitinfrastruktur von Grund auf neu zu entwickeln, und die Zeit bis zum stabilen Betrieb verkürzte sich erheblich. Die drei GPUs taten endlich das, wofür sie gedacht waren: den KI-Code des Kunden ausführen, statt um CPU-Zyklen mit dem Netzwerk-Stack zu kämpfen. Die Kameras waren nie das Problem, die Datenpipeline war es.
Was viele Integratoren zunächst als CPU-Problem wahrnehmen, ist bei genauerer Betrachtung vor allem ein Memory-Bandwidth-Problem. In klassischen GVSP-Implementierungen durchläuft der eingehende Bilddatenstrom mehrere Pufferkopien. Jede dieser Kopien belastet die Speicherbandbreite, und bei hohen Datenraten mit mehreren gleichzeitigen Kamerastreams sättigt diese kumulierte Last das System, noch bevor die CPU selbst zum limitierenden Faktor wird. Das Ergebnis: Frameverluste, instabiles Verhalten und ein Host-System, das unter Last kollabiert, obwohl die CPU-Auslastung auf dem Papier noch Spielraum zeigt. Emergent hat dieses Problem durch eine Zero-Copy-GVSP-Architektur gelöst. Statt Bilddaten durch aufeinanderfolgende Speicherpuffer zu leiten, landet der Datenstrom in einem einzigen Transfer direkt am Zielort in der Applikation. Das eliminiert bis zu 3x den Memory-Bandwidth-Overhead klassischer Ansätze und reduziert die CPU-Interaktion auf das vom Standard geforderte Minimum. Wie Bild 3 zeigt, ist der Unterschied zwischen einer konventionellen GVSP-Implementierung und einer Zero-Copy-Architektur erheblich und wächst mit jeder weiteren Kamera, die dem System hinzugefügt wird.
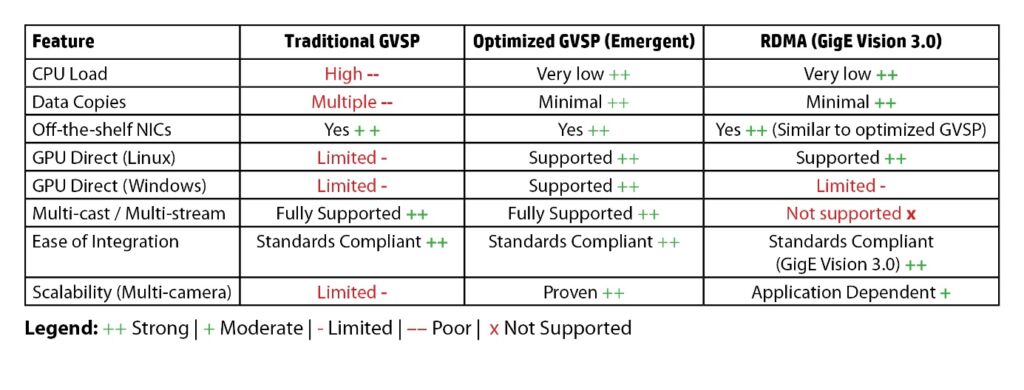
RDMA und GigE Vision 3.0
Die nächste Entwicklungsstufe ist der kommende GigE Vision 3.0 Standard, der native Unterstützung für RDMA (Remote Direct Memory Access) einführt. RDMA realisiert Zero-Copy-Datentransport auf Standardebene: Netzwerkschnittstellen übertragen Bilddaten direkt in die Anwendungsspeicherbereiche, ohne Zwischenkopien und ohne dass die CPU jedes einzelne Paket verarbeiten muss. Im Kern adressiert RDMA damit dasselbe Memory-Bandwidth-Problem, das Emergents Zero-Copy-GVSP-Architektur seit Jahren löst, macht diesen Ansatz aber nun für einen breiteren Markt zugänglich. Zum Zeitpunkt dieser Veröffentlichung befindet sich der Standard voraussichtlich in der finalen Ratifizierungsphase oder ist bereits verabschiedet.
Das Zero-Copy-Prinzip bildet seit Beginn den Kern der GVSP-Implementierung von Emergent, entwickelt aus der Notwendigkeit für hochbandbreitige Multi-Kamera-Umgebungen, in denen kein Spielraum für architektonische Ineffizienz bestand. GigE Vision 3.0 bringt diese Möglichkeit nun auch einem weiteren Anbieterkreis, und Emergent ist in der Position, beide Wege zu unterstützen. Bestimmte Implementierungen mit RDMA bringen aber Einschränkungen bei Multicast-Streaming mit sich, das in skalierbaren Multi-Kamera-Systemen nach wie vor eine wichtige Rolle spielt. Wie Bild 4 zeigt, hat jeder Transportansatz seine eigenen Eigenschaften, und die richtige Wahl hängt vom vollständigen Systemkontext ab, nicht von den Bandbreitenzahlen alleine.
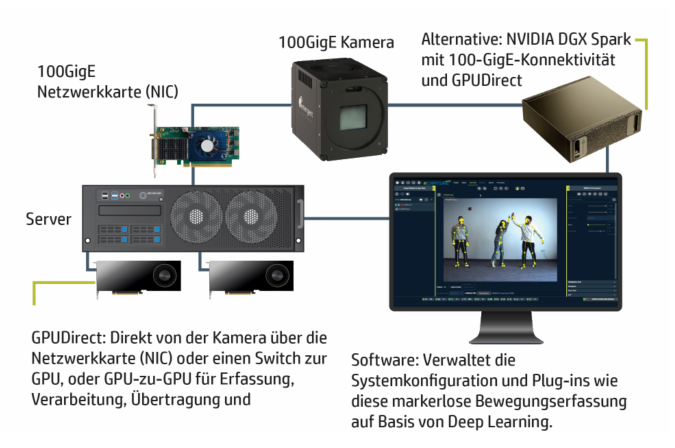
Vom Kamerastream zur Datenpipeline
Sobald die Bilddaten das Host-System erreichen, beginnt die eigentliche Arbeit. Moderne High-Performance-Systeme setzen zunehmend auf GPU-basierte Verarbeitungspipelines für Inspektion, Rekonstruktion oder KI-Inferenz, und schon der effiziente Transport der Daten von der Netzwerkschnittstelle in den GPU-Speicher ist eine eigenständige Ingenieuraufgabe. Technologien wie GPU Direct unter Windows ermöglichen eine direkte Weitergabe der Bilddaten von der Netzwerkkarte in den GPU-Speicher mit minimalem Overhead und umgehen dabei den CPU-Flaschenhals, der den Durchsatz andernfalls begrenzen würde. In der Praxis ist die effiziente Integration dieser Mechanismen in eine Applikationspipeline jedoch anspruchsvoll, insbesondere wenn mehrere hochbandbreitige Streams gleichzeitig verarbeitet werden müssen. In Multi-Kamera-Umgebungen mit Gesamtdatenraten von mehreren zehn oder hundert Gbps muss die Integration von Kameraschnittstelle, Systemspeicher, GPU-Pipeline und Storage von Anfang an durchgängig gedacht werden. Wie Bild 6 zeigt, reichen diese Architekturen von kompakten Edge-Systemen mit einer einzelnen Kamera bis zu großen Multi-Kamera-Installationen mit Switch-Infrastruktur und mehreren GPU-Workstations. Der Kontrast zu klassischen Framegrabber-Systemen ist dabei erheblich: Ethernet-basierte Lösungen skalieren flexibel über Standard-Netzwerkinfrastruktur, während Framegrabber-Architekturen dedizierte Hardware pro Kameragruppe erfordern und mit jeder Erweiterung an Komplexität und Kosten zunehmen.
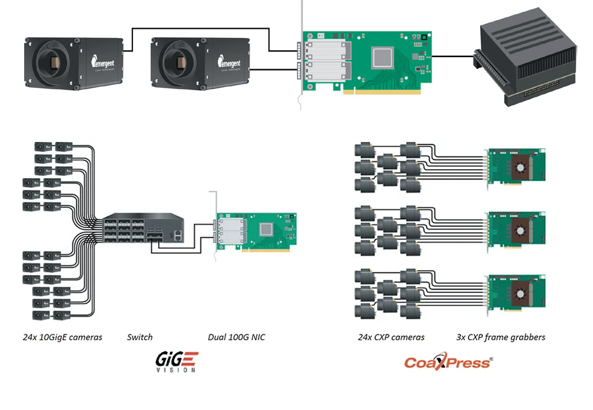
Stabilität und Kosteneffizienz
Auch die wirtschaftliche Dimension spielt eine Rolle. In manchen Highspeed-Projekten wird Stabilität durch das schlichte Hinzufügen von Hardware erkauft: mehr Server, zusätzliche Netzwerkkarten, separate Processing-Nodes zur Lastverteilung. Das kann funktionieren, führt aber häufig zu komplexen und teuren Architekturen. Wer Datentransport optimiert, CPU-Overhead reduziert und effiziente Verarbeitungspipelines von Grund auf entwirft, kann deutlich mehr Kameras auf weniger Host-Systemen betreiben. Stabile Multi-Kamera-Installationen erfordern daher keinen Ein-Kamera-pro-Rechner-Ansatz. Sorgfältig ausgelegte Systeme skalieren auf Dutzende von Kameras, ohne dass Hardware-Anforderungen und Betriebskomplexität außer Kontrolle geraten, und genau dieses Gleichgewicht aus Leistung, Stabilität und Kosten entscheidet oft darüber, ob ein Highspeed-Projekt den Weg in die Produktion schafft oder nur Konzeptnachweis bleibt. Um die Integration zu vereinfachen, bieten Software-Frameworks wie eSDK Pro Zugang zu optimierten Datenpfaden einschließlich GPU Direct. Statt aufwendiger Low-Level-Entwicklung können sich Systemdesigner auf die Applikationslogik konzentrieren und vermeiden hunderte von Entwicklungsstunden für Transport, Speicherverwaltung und schnittstellenseitige Optimierung, die beim Aufbau hochperformanter Visionpipelines sonst anfallen.
Fazit
Mit Sonys neuester Sensorgeneration und GigE Vision 3.0, das RDMA-Unterstützung in den breiten Markt bringt, beginnt eine neue Phase der Highspeed-Bildverarbeitung. Leistungsstarke Sensoren, hochbandbreitige Ethernet-Infrastruktur und moderne GPU-Rechenarchitekturen wachsen auf eine Weise zusammen, die Anwendungen ermöglicht, die bisher für die meisten Systemintegratoren nicht möglich waren. Mehr Unternehmen werden diesen Bereich erschließen, und die Technologie selbst wird sich zügig weiterentwickeln.
Was ein Jahrzehnt realer Deployments dabei aber immer wieder zeigt: Die Kameraspezifikation entscheidet selten über den Projekterfolg. Die Systeme, die in der Produktion zuverlässig funktionieren, sind jene, bei denen jede Stufe der Bildverarbeitungspipeline mit dem vollständigen Datenfluss im Blick ausgelegt wurde: vom Sensor zur Schnittstelle, von der Schnittstelle zum Host, vom Host-Speicher zur GPU und weiter in Richtung Storage oder Ausgabe. Die erwähnte Lebensmittel-Inspektionslinie mit 21 Kameras, die zwei Jahre lang ohne funktionierende Lösung lief, ist kein Einzelfall, sondern eher die Regel. In der Highspeed-Bildverarbeitung war die Kamera nie der eigentliche Flaschenhals. Die Systemarchitektur ist es. Diese richtig hinzubekommen erfordert etwas, das kein Datenblatt liefern kann: Erfahrung aus echten Projekten, in echtem Maßstab und unter echten Bedingungen.