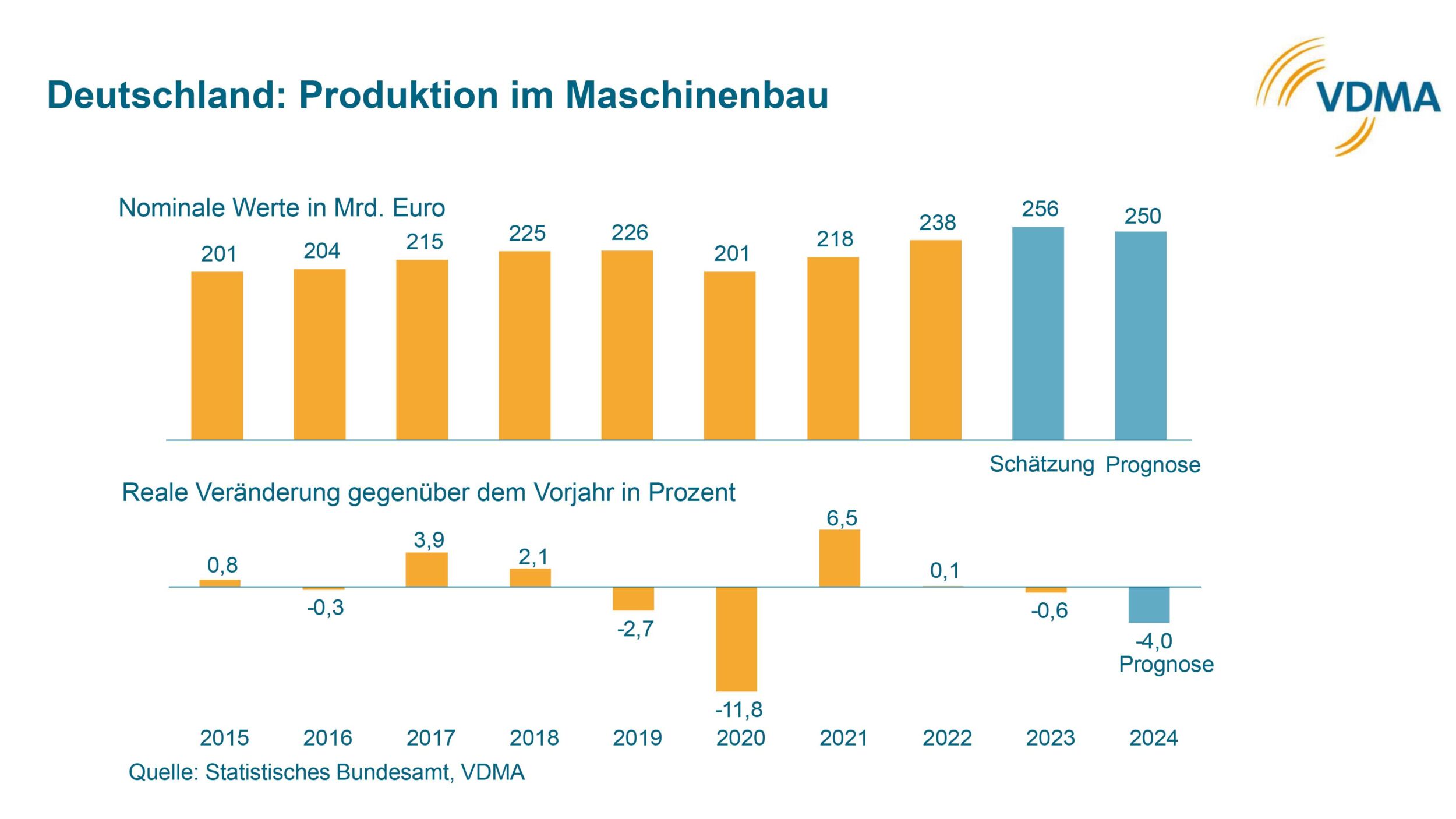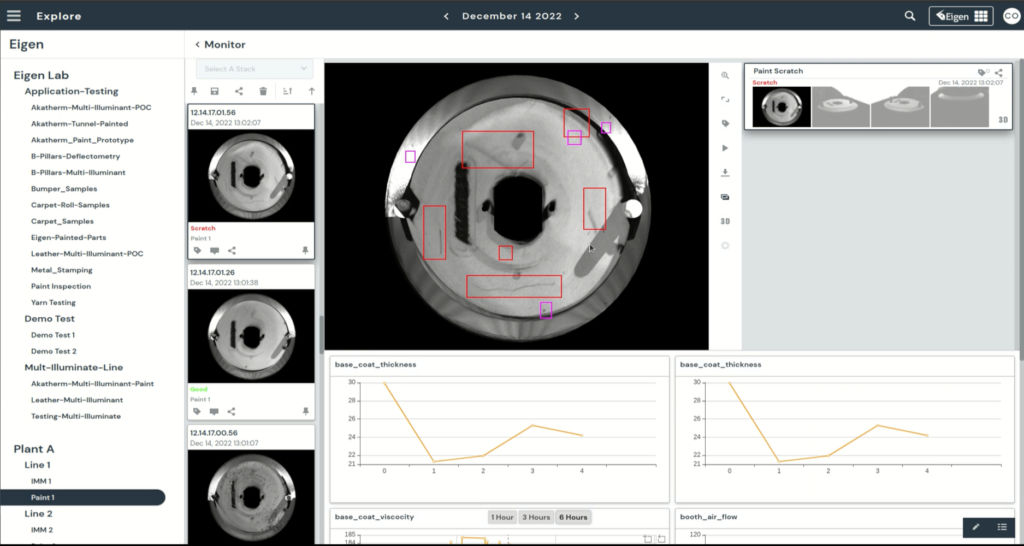
Spätestens seit dem ChatGPT-Hype ist das Zukunftspotential von KI in keinem Anwendungsbereich mehr wegzudenken, erst recht nicht in der industriellen Bildverarbeitung. Doch der Wechsel von klassischen Algorithmen hin zu Deep-Learning geht nur stockend voran. Ein Hauptgrund hierfür ist die Schwierigkeit, ausreichend Bildmaterial für das Training eines zuverlässigen Modells zu sammeln. Ein Ansatz zur Umgehung dieses Problem sind synthetische Daten. Aber wäre es nicht schlauer, die Bildvarianten an der Quelle zu reduzieren, statt sie abzubilden?

Reale und synthetische Trainingsdaten
Die Qualität und Zuverlässigkeit eines Deep Learning Modells beruht hauptsächlich auf der Qualität seiner Trainingsdaten. Je mehr Bilder des Prüfobjekts in allen Variationen mit und ohne Defekten zur Verfügung stehen, desto besser die Leistung des Modells. Doch gerade das stellt sich oft als eine Herausforderung für Systementwickler heraus. Bei einer neuen Fertigungslinie bzw. einem neuen Produkt fehlt ein ausreichendes Bildarchiv, um das Modell zu trainieren. Neben der Vielfalt an möglichen Defekten kommt oft hinzu, dass die Abbildungen des Objekts nicht einheitlich sind. So liegt zum Beispiel das Bauteil an unterschiedlichen Stellen und in unterschiedlichen Orientierungen und Perspektiven auf einem Fließband, sodass nahezu jedes Bild in seiner Komposition anders ist als die anderen. Auch auf diese Vielfalt muss das Modell trainiert werden. Soll das Bildverarbeitungssystem nicht nur an einer, sondern an mehreren Maschinen, Fertigungslinien oder sogar Standorten ausgerollt werden, multipliziert sich diese Vielfalt an Bildvarianten entsprechend, da jede Maschine eine etwas andere Kameraausrichtung, ein anderes Licht usw. hat.
Ein Trick, um die Menge an Trainingsdaten zu erhöhen, sind synthetische Daten. Dies sind Daten, die nicht tatsächlich vom System erfasst wurden, sondern von realen Daten abgeleitet sind, um zusätzliche Varianten künstlich zu generieren. Bei Bilddaten können zum Beispiel existierende Bilder rotiert oder gespiegelt werden. Eine anspruchsvollere Form von synthetischen Daten sind 3D-Renderings des Produkts, mit denen verschiedene Kameraperspektiven bzw. Produkteigenschaften simuliert werden. Durch eine Kombination aus möglichst vielen echten und synthetischen Daten bemühen sich Entwickler, die vielen Varianten an Bilddaten, die später im Normalbetrieb entstehen, in den Trainingsdaten des Deep Learning Modells wortwörtlich abzubilden.

Tool für Bildnormalisierung
Es geht aber auch anders, indem unnötige Variationen an der Quelle eliminiert werden – etwa unterschiedliche Objektposition im Bild, Rotation, Perspektive, Hintergrund etc., die keinen Mehrwert für die Qualitätsprüfung haben. Bei diesem Ansatz werden nicht die von den Kameras erfassten Originalbilder vom Algorithmus verarbeitet, sondern sogenannte Digital Twins. Dies sind standardisierte, künstlich erzeugte Ansichten, die jede Variation in Position, Rotation, Perspektive etc. eliminieren. Eigen Innovations hat die Vorteile dieses Paradigmenwechsels erkannt und ein Softwaretool entwickelt, mit dem eine solche Bildnormalisierung durchgeführt wird. Eigen Image Twin vereinheitlicht die Bilddaten dadurch, dass das Bildmaterial aus einer oder mehreren Kameras als Textur mit den CAD-Daten des Bauteils zusammengeführt wird. Mit diesem 3D-Objekt kann wiederum eine einheitliche Perspektive generiert werden. Die standardisierten Bilddaten werden sowohl für das Training des Modells benutzt als auch später für die Prüfaufgabe im laufenden Betrieb.
Skalieren über mehrere Standorte
Dieser Vorgang eliminiert alle unnötigen Variationen und bringt viele Vorteile:
- In der Trainingsphase werden weniger Trainingsdaten benötigt, da das Modell mit einer einheitlichen Ansicht sich nur auf eins konzentriert: Fehler zu identifizieren. Durch diese Vereinfachung lässt sich das Deep Learning Modell schneller trainieren, ohne die Zuverlässigkeit zu beeinträchtigen.
- Dadurch, dass die Bilddaten normalisiert sind, können Daten aus verschiedenen Maschinen bzw. Fertigungslinien in den Trainingsdatensatz einfließen. So lässt sich schneller die kritische Masse für ein robustes Modell erreichen.
- Im Umkehrschluss macht diese Standardisierung das Deep Learning Modell im hohen Maß skalierbar: es kann in jedem Bildverarbeitungssystem an jedem Standort ausgerollt werden, ungeachtet möglicher Variationen in der Bilderfassung, denn die Variationen werden von Image Twin herausgefiltert.
- Diese Skalierbarkeit macht das System lernfähiger: wird ein neuer Defekt an einer Maschine entdeckt, lernen alle Maschinen beim nächsten Modell-Update daraus. So profitiert ein Werk in Mexiko automatisch von der Erfahrung des Werks in Frankreich.
- Über die eigentliche Prüfaufgabe hinaus ermöglicht die einheitliche Produktabbildung erweiterte Analysen zur fertigungslinien- und standortübergreifenden Qualitätssicherung. Hierzu hat Eigen Innovations eine eigene Cloud-Plattform entwickelt, die die Bild- und Prüfdaten mit anderen Prozessdaten korreliert, um Defekte nicht nur zu erfassen, sondern auch ihre Ursachen zu ermitteln.
www.eigen.io