Die Erwartungen an eine OCR (Optical Character Recognition) sind hoch. Heutzutage erwarten Anwender, dass sie alle Zeichen out-of-the-box erkennt und richtig deutet. Darüber hinaus sollte die Genauigkeit konsistent bleiben, unabhängig von Veränderungen in der Lichtsituation oder anderen Umgebungsbedingungen. Regelbasierte Ansätze haben den Nachteil, dass ihnen der Interpretationsspielraum fehlt, der bei Ansätzen mit neuronalen Netzen durch das Training mit vielen verschiedenen Beispielen erworben wird. Alleine der Einsatz modernster Technologie ist jedoch nicht ausreichend für den Projekterfolg – vielmehr geht es auch darum, OCR einfach und performant nutzbar sowie benutzerfreundlich wartbar anzubieten. Allerdings schon die reine Vielfalt an möglichen Schriftzeichen und Verfahren, wie Zeichen auf den verschiedensten Oberflächen angebracht werden, vermittelt eine Vorstellung der Herausforderungen. Die Schwierigkeiten solche komplexe visuelle Daten in strukturierte Texte umzuwandeln, umfassen Schmutz, Reflexionen sowie Formfehler durch Ritzen, Prägungen oder Lasergravuren auf festen Materialien. Zudem können überlagerte oder unvollständige Zeichen, sowie eine niedrige Pixelauflösung der Bilddaten dazu führen, dass sich Zeichen kaum mehr voneinander unterscheiden lassen. So wird z.B. eine 8 schnell zu einer 3. Was sind daher die entscheidenden Faktoren für die Auswahl eines OCR-Systems?
Reproduzierbare Genauigkeit
Eine OCR muss von Anfang an einfach funktionieren und eine hohe Leseleistung bieten, um zu überzeugen. Dazu bedarf es einer gut entwickelten Netzarchitektur, die mit vielen variantenreichen Trainingsbildern vortrainiert wurde. Hier sind Situationen aus realen Anwendung genauso unverzichtbar wie der Einsatz synthetischer Daten. Damit können nicht nur viele Sonderfälle und Variationen gelernt werden, das sorgt auch für eine weitaus robustere Erkennung der relevanten Merkmale. An dieser Stelle setzt Denknet an, die KI Vision-Lösung für individuelle Bildanalysen. Dort steht Anwendern ein performantes und ständig weiterentwickeltes Deep-OCR-Modell zur Verfügung. Alle Entwicklungsschritte sind dabei streng versioniert, sodass Anwendungsentwicklungen auf definierte Versionen zurückgreifen können, aber auch die Möglichkeit haben, auf eine neue verbesserte Version zu aktualisieren. Zur Qualitätssicherung kann die Performance und Reproduzierbarkeit der trainierten Netze in einem Quality Center gegen Beispieldatensätze geprüft und verifiziert werden, bevor eine Produktionsanlage mit der neuen Software aktualisiert wird.
Transformer & Large Language Models
Eine weitere Eigenschaft eines guten OCR Modells liegt in der Fähigkeit, nicht nur einzelne Zeichen, sondern die Zusammenhänge – bei Zeichenfolgen, wie bspw. Seriennummern oder Worten – zu erkennen und dieses Wissen auch zu berücksichtigen. Je besser die OCR auch Folgezeichen vorhersagen und das Leseergebnis damit gewichten kann, desto robuster und präziser können spezielle Anwendungsfälle gelöst werden. Die generativen und kombinatorischen Eigenschaften von Transformer-Netzen oder Large Language Modellen (LLM), wie sie ChatGPT verwendet, könn(t)en solche Vorhersagen und damit auch die Lesequalität positiv beeinflussen. Doch dabei sollte man bedenken, dass diese Architekturen in der Ausführung eher langsam sind und viele Systemressourcen benötigen. Gerade im Automatisierungsbereich sollte sich eine Bildverarbeitung nicht im Sekunden-, sondern eher im niedrigen Millisekunden-Bereich bewegen. Ein trainiertes neuronales Netz sollte deshalb schnell und leichtgewichtig bleiben, um es auch auf ’normaler Hardware‘ ausführen zu können.
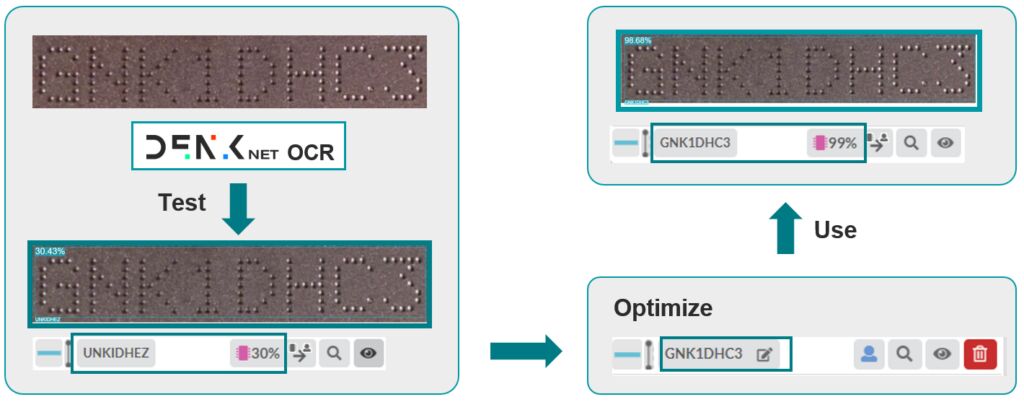
Einfaches Korrigieren und Nachtrainieren
Sollte die OCR doch mal Zeichen nicht lesen, ist es wichtig, dass der Anwender mit wenig Aufwand das Leseergebnisse korrigieren oder auch neue Zeichen trainieren kann. Bei diesem Feintuning handelt es sich allerdings nicht um ein einfaches ‚Weiter‘-Trainierendes Netzes. Man stelle sich vor, dass das OCR-Modell beispielsweise mit zwei Millionen Bildern trainiert wurde und der Benutzer dem Modell nun mit einigen wenigen Bildern etwas Neues beibringen möchte. Mit welcher Gewichtung geht eine solche Information in das Modell ein, um zwar etwas zu bewirken, dabei aber auch nicht alles zu verändern? Genau hier ist das Know-how des Anbieters gefragt, die KI so zu erweitern, dass durch eine derartige Anpassung nicht bisherige stabile Erkennungen negativ beeinflusst werden. Ein Beispiel: Eine OCR hat Probleme mit Zahlen und der Anwender annotiert im Trainingsprozess nur Zahlen, nie Buchstaben. Dabei gilt es durch eine intelligente ‚Wissenssicherung‘ zu verhindern, dass das Netz irgendwann nur noch Zahlen erfolgreich lesen kann, weil es denkt, es müsse keine Buchstaben erkennen. Der Denk Vision KI Hub generiert deshalb beim Feintuning der Denknet OCR für alle neuen Bilddaten passende künstliche Daten, um das Netz im richtigen Maß weiter zu trainieren und zu gewichten. Das verhindert, dass die OCR, egal wie lange sie weitertrainiert wird, ihre bisherigen Fähigkeiten verliert. Dabei bleibt das Nachtrainieren für den Benutzer des Vision KI Hubs einfach in der Handhabung und durch das Cloud-basierte Training im Hintergrund schnell und performant.
Cloud-Training
Alle Funktionen und Dienste des Denk Vision KI Hub basieren vollständig auf Cloud-Technologie. Dadurch findet das Feintuning auf eigenen Bilddaten auf einer stets aktuellen und kontrollierten Software-Basis statt und nicht auf irgendeiner Software-Version auf einem lokalen Hardwaresystem. Das dort verwendbare OCR-Modell wird durch die kontinuierliche Weiterentwicklung im technischen Backend immer resistenter gegenüber bereits gelösten Problemen. Dadurch können immer mehr Kundenanwendungen ohne größere Anpassungen oder Nachtraining verwendet werden. ‚Press Play‘ ist wie ein Auftrag an die Denkcloud, die im Hintergrund eine Vielzahl passender Netzmodelle mit unterschiedlichen Architekturen trainiert und dem Anwender letztendlich das beste Ergebnis zur Verfügung stellt.
Auch im Supportfall hat die Cloud-Lösung ein Mehrwert für den Anwender. Sollte es mit Daten eines Use-Cases Schwierigkeiten geben, z.B. bei unbekannte Schriftzeichen, kann technische Unterstützung im Backend schnell Abhilfe schaffen. Ohne Daten exportieren/importieren zu müssen oder die Gefahr dass unterschiedliche Buildsysteme oder Software-Versionen zu unterschiedlichen Ergebnissen führen, können beispielsweise Änderungen an der Netzarchitektur vorgenommen oder die Erzeugung synthetischer Zusatzdaten optimiert werden. Das geht im direkten Austausch, ohne Zeitverlust direkt im Kunden-Use Case. Der Verzicht auf den Versand sensibler Daten minimiert zudem das Risiko eines unbefugten Zugriffs.