Defekte aus der Simulation
Im grauwertbasierten CT-Bild zeichnen sich Gussfehler als dunkle Bereiche ab. Die Frage, die sich der Qualitätstechniker dabei stellt, ist stets: Welche Voxel gehören zum Defekt und welche nicht? (Voxel=kleinstes 3D-Element im CT-Modell, ähnlich Pixel im 2D-Bild.) Überlässt man die Annotation, d.h. die Markierung der Voxel entweder als Defektvoxel oder kein Defektvoxel einer Reihe von Labortechnikern, so stehen sich am Ende, meist unterschiedliche Detaileinschätzungen gegenüber. „Für das Training des KNN schied diese Herangehensweise daher aus“, erklärt Patrick Fuchs, Software Engineer bei Volume Graphics. „Wir entwickelten stattdessen eine vollautomatische Annotation mit Hilfe einer Simulations-Pipeline.“ Dafür entwarfen die Heidelberger CT-Spezialisten verschiedene CAD-Modelle von realistischen Aluminiumwerkstücken, gespickt mit typischen Details wie Bohrungen, Gewinden, Nuten usw. Ein nächster Arbeitsschritt bestand darin, reale Defekte, wie sie in Aluminiumbauteilen vorkommen, genau zu analysieren. „Mit diesen Erkenntnissen“, so Fuchs weiter, „entwickelten wir einen Algorithmus, der nach realen Vorbildern ca. 700.000 Defekte generierte, die wir als Mesh-Modelle abgespeichert und in den CAD-Modellen platziert haben. Der Algorithmus erzeugte die Defekte mit zufälligen Formen, aber nach einheitlichen Mustern. Poren haben z.B. immer eine runde Form, Lunker sind aufgerissen und haben viele Ecken und Kanten.“ Im nächsten Schritt bediente sich Volume Graphics der Simulationssoftware aRTist der Bundesanstalt für Materialforschung und -prüfung (BAM), um aus den CAD-Modellen mit ihren Defekten realitätsgetreue CT-Projektionen zu erzeugen (s. Beitrag auf S. ??). Diese bilden die Ausgangsdaten, die auch der Computertomograph in der realen Welt ausgibt. Effekte wie Streustrahlungen oder Artefakte wurden von der Software ebenfalls simuliert. Die so erhaltenen CT-Rohdaten wurden schließlich mit VGinLine zu Voxelmodellen rekonstruiert.
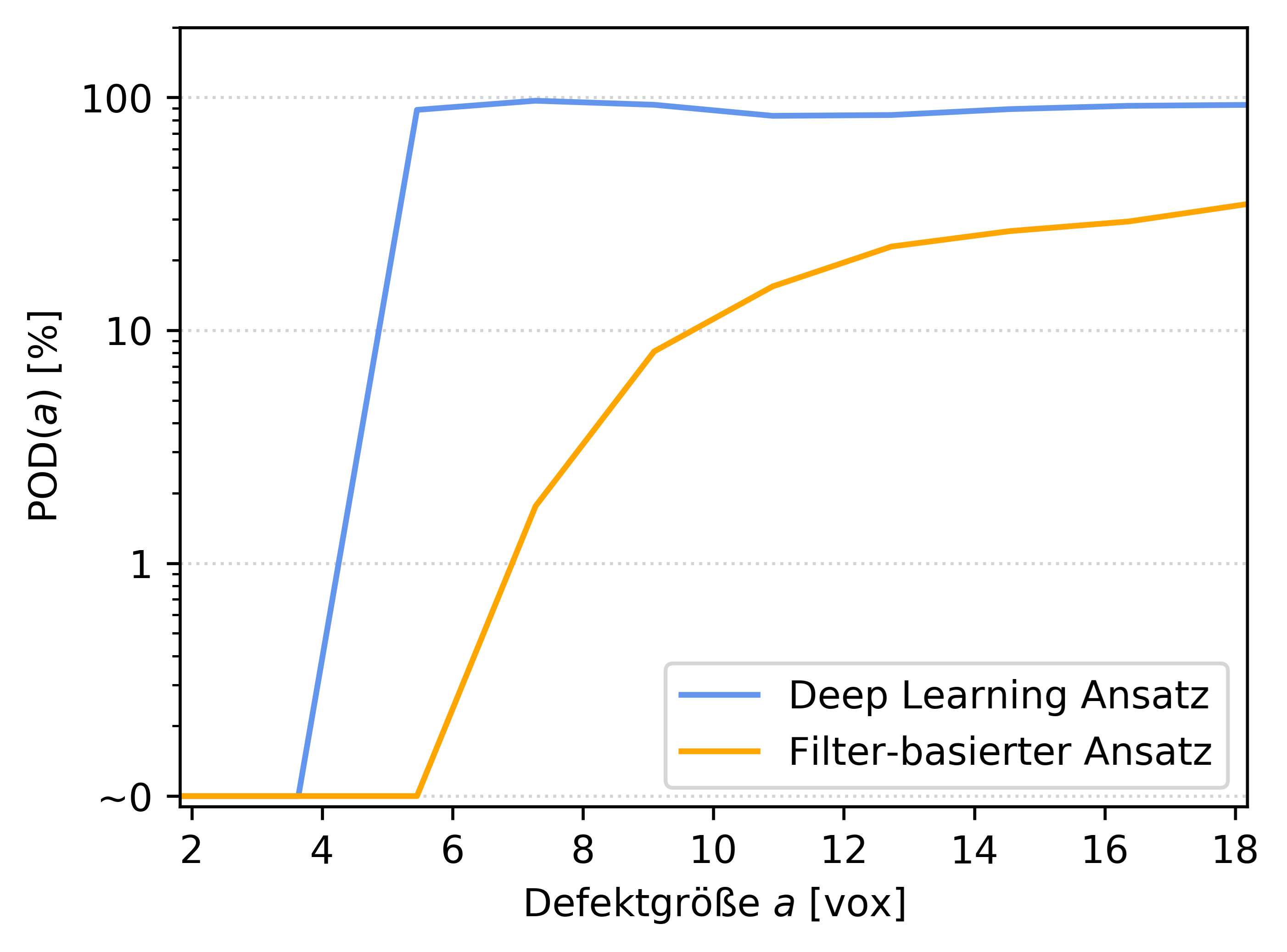
Bild 3 | Die Probability of Detection (PoD) zeigt, dass die Deep-Learning-Methode kleinere Defekte findet als der klassische filterbasierte Ansatz. Auf der x-Achse sind die Defektgrößen nach Anzahl der Voxel aufgetragen. Bereits bei weniger als 4 Voxeln steigt die Kurve schnell an. Ab einer Defektgröße von etwa 5 Voxeln findet das KNN so gut wie 100% aller Defekte. Die klassische Methode wird erst später fündig und kommt in keinem Falle auf 100%. Getestet wurde der Zusammenhang mit einem schwer zu detektierenden Datensatz mit geringen Kontrasten und hoher Artefaktbehaftung. Ein besseres Abschneiden des filterbasierten Ansatzes wäre möglich, aber nur mit entsprechendem Aufwand (hohe Auflösungen, lange Scanzeiten, lokale Filteranwendung auf Regions of Interest usw.). (Bild : Volume Graphics GmbH)
Training mit präzisen Fehlerdaten
Die Ausgangsfrage – Welche Voxel gehören zum Defekt und welche nicht? – lässt sich für dieses Datenmaterial leicht beantworten: da es sich um simulierte Modelle handelt, sind die Defekte in Gestalt und Ausmaß bekannt. Wenn man das KNN mit diesen Daten trainiert, hat es die typischen Defektformen von Aluminiumbauteilen quasi intus. „Es ist elementar wichtig, das Netz mit präzisen Daten zu trainieren, um später genaue Ergebnisse zu erhalten“, betont Patrick Fuchs, „denn das KNN soll Ähnlichkeiten zwischen den simulierten Defekten und den Defekten neuer, realer Bauteile feststellen.“ Anders gesagt: Ein KNN findet nur, womit es gefüttert wurde. Erstreckt sich das Training nur auf Daten von Poren, wird es nur Poren finden. Die anschließende Evaluierung belegt, dass ein so trainiertes KNN sehr gut funktioniert und den klassischen Methoden in jeder Hinsicht überlegen ist, es findet sogar kleinere Defekte, und zwar problemlos. Zwei Qualitätskennzahlen quantifizieren den Sachverhalt anschaulich (s.Kasten): die Probability of Detection (PoD) und die Intersection over Union (IoU) . Die PoD kommt auch sonst in der Qualitätstechnik zu Anwendung. Sie ist ein Kriterium, ob Defekte überhaupt gefunden werden bzw. ab welcher Größe. Die IoU, auch als Jaccard-Index oder -koeffizient bezeichnet, kommt aus der Mengenlehre und wird häufig in der Bilderkennung verwendet. Im hier vorliegenden Anwendungsfall gibt die IoU voxelgenau Aufschluss über die Segmentierungsqualität. Wichtig dabei, die Ergebnisse gelten initial nur für Fehler in Aluminiumwerkstücken, worauf das KNN trainiert wurde. Patrick Fuchs dazu: „Hat man aber einmal ein trainiertes Netz vorliegen, ist der Aufwand, es auf andere ähnliche Anwendungen zu trainieren, überschaubar. Die Anwendung auf Kunststoffe oder andere Metallwerkstoffe ist also im Prinzip jederzeit möglich.“
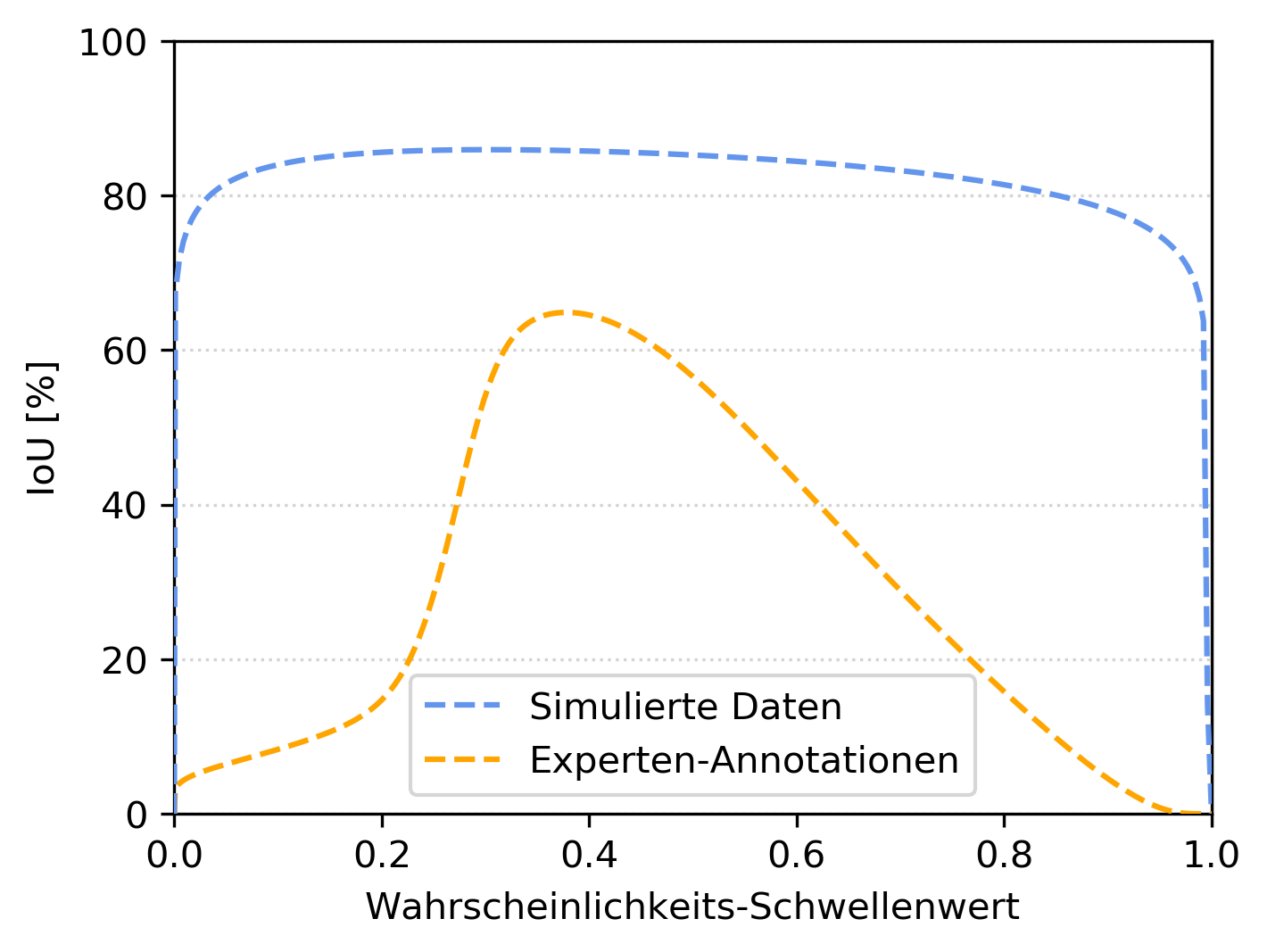
Bild 4 | Die Intersection over Union (IoU) zeigt in Prozent, inwieweit die Vorhersagen der KNN voxelgenau mit den realen Annotationen, der Ground Truth, übereinstimmen. Dem Diagramm oben liegt ein Evaluierungsdatensatz mit 54 Defekten zugrunde. Eine niedrige IoU, bedeutet, dass bei der Beantwortung der Ausgangsfrage („Welche Voxel gehören zum Defekt, welche nicht?“), viele Voxel falsch interpretiert wurden. Dies kommt auch bei der herkömmlichen Experten-Annotation sehr häufig vor. Der Wahrscheinlichkeits-Schwellenwert auf der X-Achse (0 = kein Defekt, 1 = Defekt) zeigt, stark vereinfacht gesprochen, dass die Deep-Learning-Methode die robusteren Ergebnisse liefert. Der Übergang Defekt/nicht Defekt ist schärfer. Die klassische Vorgehensweise zeigt im Vergleich dazu eine große Streuung. (Bild Volume Graphics GmbH)









